Weaving data fabric into hybrid multicloud
Everyone involved in technology-driven business transformation should understand the concept of data fabric. As large enterprises continue to evolve in response to constant competitive pressures and unforeseen events such as the current pandemic, data fabric will help many of them “pass their genes” along to their organizations’ future iterations. Today, enterprise investments in expanded data and data analytics capabilities continue to be strong, as are investments in hybrid multicloud architectures. As software “eats the world,” it is doing so on a high-protein diet of intelligent data and hybrid cloud.
IBM Institute for Business Value research shows that getting more value from data drives sound digital strategies. Outperformers are making enterprise-scale investments in data centers of excellence (CoEs), data scientists, and data analytics tools. Most large enterprises today have strategies for infusing customer-facing applications—digital products—with information that improves the customer’s experience, supports customer journeys, and makes new services possible. These strategies work in B2B as well as B2C business models and are central to emerging platform business models as well.
Data fabric provides new ways to manage the boundaries separating applications, data, clouds, and the people who design and create them.
Technology plus scale plus people equals complexity. We tend to manage complexity by drawing boundaries around things, allowing us to focus on one part of a complex system at a time. This works up to a point, but we often ignore the crucial business of managing the white space between the boundaries we’ve drawn. Data fabric is important to understand because it provides new ways to manage the boundaries separating applications, data, clouds, and the people who design and create them. It’s the management of those boundaries that determines success.
This report explores three of those boundaries. First are the boundaries between data platforms. Second are the boundaries between clouds and cloud providers. The third are the boundaries between the enterprise’s transactional and analytical data operations and communities.
Boundaries between data platforms
A saying common among data practitioners is, “once you add a second database, you have an integration problem.” In the years since big data was the king of IT buzzwords, the opportunities to profit from better use of data have compounded, but at a rate fully matched by the challenges of making the right data available to the right applications at scale. Even before the cloud, enterprises were building data platforms: technology solutions that integrate data located in diverse databases. Data platforms are designed to act as a service. Within guardrails, people who need data can get access to it or have it delivered to users, applications, or other technologies.
The boundary around each data platform is usually defined by the type of data it stores, or by the way that the data is used. Large enterprises might need an HR data platform, or a supply chain data platform, or a customer data platform for a specific business unit.
The data needed to build and operate an end-to-end view of the customer value chain is unlikely to be located in any single data platform.
Those boundaries made sense and were an expedient way to get more value from the data available. But today, several changes have made a difference. First, as enterprises deploy new business models and build single views of lifetime customer interactions, business unit silos of customer data are less defensible. Second, as supply chains become increasingly digitized, the data needed to build and operate an end-to-end view of the customer value chain is unlikely to be located in any single data platform. Third, better data analytics mean that there may be connections and insights available across data platforms that would not have occurred to their designers.
There are three approaches to manage the boundaries between data platforms: consolidate, connect, and control. Any of these methods could be part of a data fabric, but the one most suited to a distributed, hybrid cloud environment is the third option. For every method, however, the critical thing is to loosely couple the data in the platforms with the applications that need it. This concept of loose coupling is important throughout data fabric architectures.
Boundary strategies: Three approaches for managing data platform boundaries
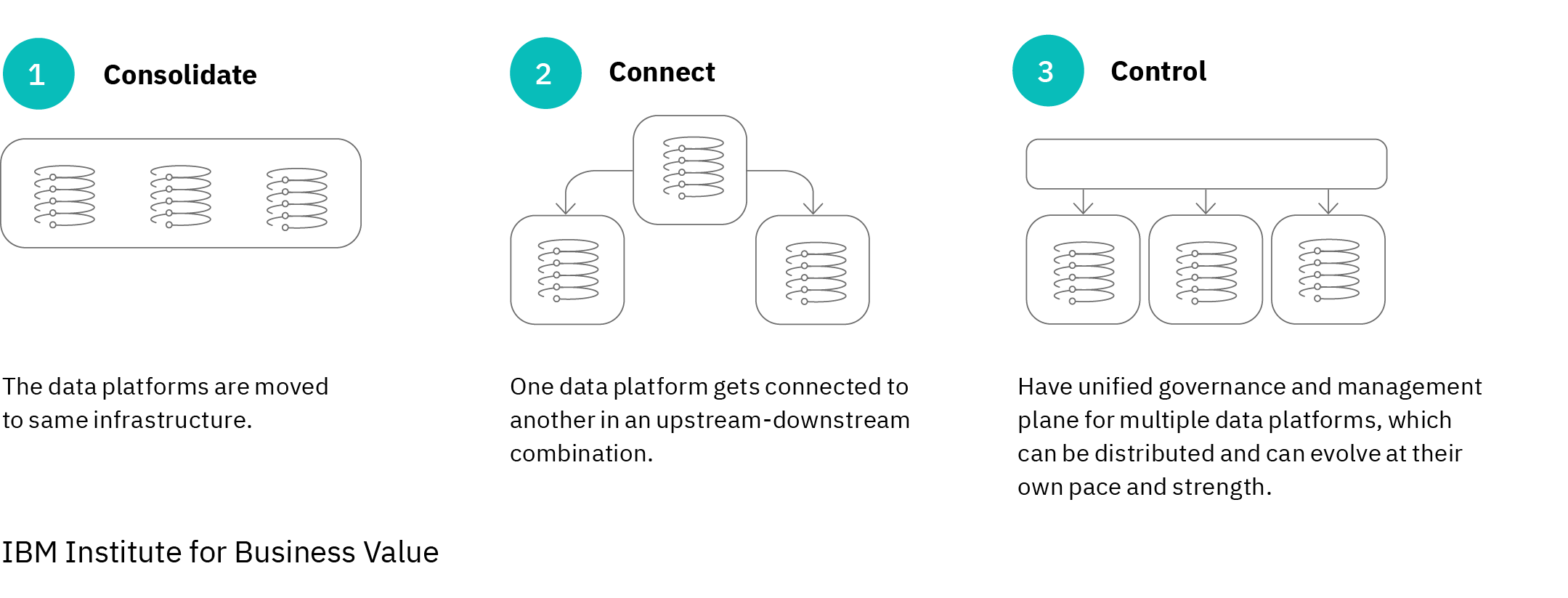 Read the full report to see how your organization can move beyond the database—and create an environment where the right data is available to the right location and the right application at the right time.
Read the full report to see how your organization can move beyond the database—and create an environment where the right data is available to the right location and the right application at the right time.
Meet the authors
Varun Bijlani, Global Managing Partner, Hybrid Cloud Transformation, IBM ConsultingDr. Sandipan Sarkar, IBM Distinguished Engineer, Global CTO Data, Hybrid Cloud Transformation Service Line, IBM Consulting
Richard Warrick, Global Research Leader, Cloud, IBM Institute for Business Value
Download report translations
Originally published 16 April 2021